DeScript: A Crowdsourced Corpus for the Acquisition of High-Quality Script Knowledge
Abstract
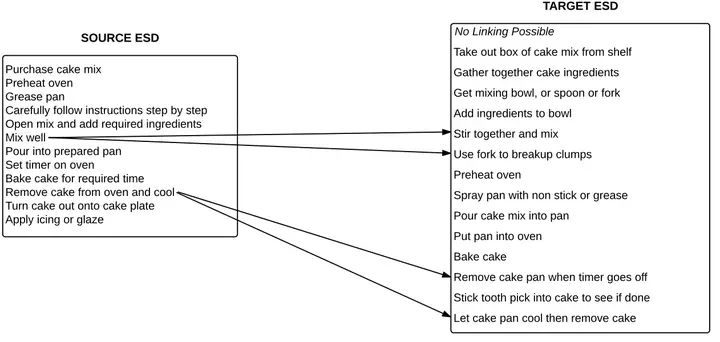
Scripts are standardized event sequences describing typical everyday activities, which play an important role in the computational modeling of cognitive abilities (in particular for natural language processing). We present a large-scale crowdsourced collection of explicit linguistic descriptions of script-specific event sequences (40 scenarios with 100 sequences each). The corpus is enriched with crowdsourced alignment annotation on a subset of the event descriptions, to be used in future work as seed data for automatic alignment of event descriptions (for example via clustering). The event descriptions to be aligned were chosen among those expected to have the strongest corrective effect on the clustering algorithm. The alignment annotation was evaluated against a gold standard of expert annotators. The resulting database of partially-aligned script-event descriptions provides a sound empirical basis for inducing high-quality script knowledge, as well as for any task involving alignment and paraphrase detection of events
Alessandra Zarcone
Professor of Language Technologies and Cognitive Assistants
Computational linguist with a background in NLP and in psycholinguistics, working on AI, NLP and human-machine interaction.